There are many developers in Windows environment who are well aware of the Unicode function but not specifically with the Unicode Windows. One could argue that this is because the majority of books do not directly demonstrate it as the first reason, and secondly because it’s concealed by Windows API. This post explores the principles of Unicode Windows for those rookie developers who are not yet familiar with this system.
#0
In order to understand the Unicode Windows, we need the full understanding of activity structure of Unicode function that Windows support. The Windows provides two primary versions of Unicode for most functions that handle the string. Multi-byte version with A is attached to, and the Unicode version which W is attached to. In other words, there’s ‘GetWindowTextA’ and ‘GetWindowTextW’. The performance of the two functions are equal, with the difference that A function gets char pointer as the parameter, while W gets ‘wchar-t’ as the parameter.
#ifdef _UNICODE
#define GetWindowText GetWindowTextW
#else
#define GetWindowText GetWindowTextA
#endifIn other words, if our build environment is under Unicode, GetWindowText becomes GetWindowTextW, while GetWindowTextA is resulted when it’s under multi-byte. This allows us to use the T typed neutral character with the system, with the neutral API which is redefined with the Macro without A and W. Moreover, the T typed neutral function on character string handling gets redefined by the macro, which allows us to generate the code regardless of the multi-byte build.
TCHAR buffer[MAX_PATH];
GetWindowText(hwnd, buffer, ARRAYSIZE(buffer));
_tcscat_s(buffer, ARRAYSIZE(buffer), _T("$"));Although development process is done with no such issues with programs adequately compiling according to the build due to the well-structured Window Subsystem, it is difficult to know the root of the issue if the conversion problem breaks out.
#1
We will now cover our main subject, the Unicode Window. One can define the Unicode Window as the Window that uses the Unicode when processing a message, which makes sense to have the ’ansi window’ on the other hand, which processes the message via multi-byte message.
If you were a developer with a little more insights, you could question what exactly it means to proceed by ‘unicode’. Here is a simple example with WM_GETTEXT message. Its WParam appoints the number of letters, while IParam appoints the buffer pointer that can save the letters. The question in this case is, Should one deliver the Unicode buffer via Iparam? Or multi-byte buffer? In other words, in the identical code as mentioned, is it right to use StringCchCopyW? Or StringCchCopyA?
LRESULT CALLBACK MyWindowProc(HWND hwnd
, UINT msg
, WPARAM w
, LPARAM l)
{
if(msg == WM_GETTEXT)
{
// StringCchCopyW((LPWSTR) l, w, L"MyWindowText");
// or
// StringCchCopyA((LPSTR) l, w, "MyWindowText");
}
return DefWindowProc(hwnd, msg, w, l);
}Most of the developers wouldn’t have wondered such issue, as Window subsystem does an excellent job of hiding it. Ultimately, we should handle ‘ansi window’ by multi-byte buffer, and Unicode window by Unicode buffer in dealing with ‘WM-GETTEXT’. In other words, you will result having an abnormally functioning window if you have multi-byte pointer handling Unicode Window, and vice versa with ansi-window.
#2
Now, we’re going to cover how Unicode Window is created. Developing the Unicode Window involves the ‘RegisterClass’ function. Although no parameter of this function has the function of categorizing the new Window into the Unicode or not, it is decided automatically depending on the type of function it’s calling out. A window becomes a Unicode window when one uses the Unicode class is
We can also identify if a particular Window is Unicode window or not by ‘Spy++ utility’. When we search through the Window and its property using Spy++, it shows ‘Unicode’ on Window Proc section. If it doesn’t have it, we can understand that it’s the ansi window.
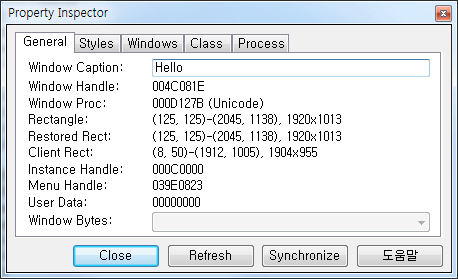
#3
However, one could wonder, why is it so important to know whether it’s a Unicode window or not? First of all, it’s because there could be an error with the handler if we didn’t know about it. As seen below, Window class registration is left under Unicode window and the particular window message procedure: for eg; ‘WM_GETTEX’ is processes via multi-byte, which will obviously cause an error.
WNDCLASSEXW wcex;
// ...
wcex.lpfnWndProc = WndProc;
return RegisterClassExW(&wcex);
LRESULT CALLBACK WndProc(HWND wnd
, UINT message
, WPARAM w
, LPARAM l)
{
if(message == WM_GETTEXT)
{
StringCchCopyA((LPSTR) l, w, "Hello");
return lstrlenA((LPSTR) l);
}
return DefWindowProcW(wnd, message, w, l)
}Secondly, this is one of the most important effect for any action related to the Window, which can complicate the system if you’re not fully aware of the system. Say for example, we are sub-classing a particular window. In this case also, we neede to use ‘SetWindowLongW’ for a Unicode, and ‘SetWindowLongA’ for multi-byte. If it were done in an opposite way, the original window message will be dealt with by the Unicode, with the procedure which sub-classes it using multi-byte system. Moreover, even when the original window is the Unicode window, it will turn into the ansi-window once the sub-classing is done via ‘SetWindowLongA’. Using the sub-classing function without the internal mechanisms as noted could cause a complicated conversion issues.
Here is another example. Most message procedure consists of creating only the critical parts, leaving the rest upto the ‘DefWindowProc’ function, which could either be ‘DefWindowProcA’ or DefWindowProcW, which is where the problem could occur with the system not responding as expected in some cases. The window below shows the similar case. The case below refers to the similar case, when ‘defWindowProcW’ is called for after creating the ANSI window using ‘RegisterClass’ A function. If it were processed correctly, it would show Hello on the title bar, but you can notice something else instead below.
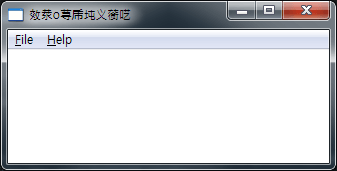
To avoid the mistakes mentioned previously, all we need is to have the understanding of the existence of Unicode and its procedure. Its procedure is that it uses W function for Windows, and A type for the multi-byte window. And lastly, that the related windows deal with messages by either Unicode or multi-byte.
#4
Knowing the existence of Unicode window and being aware of what kind of disasters you might face, one could probably wonder how we could find out whether the window we are working on is a Unicode or not. There is a very simple function for it, called “IsWindowUnicode”. If you receive a false message after you type in “IsWindowUnicdoe(hwnd), it means that you’re working on an ansi-window, while if you have other answers instead of FALSE, your Window turns out to be a Unicode.
#5
Lastly, I would like to cover a few things. For those developers who have already tested the codes, you will notice that you end up getting ‘WM_GETTEXT’ no matter which one you type in out of ‘DefWindowProcA’ or ‘DefWindowProcW’ out of the Unicode or ansi. The reason for this is simple. If its coded as protectively as shown, it can solve the character string no matter the type of window that’s used.
case WM_GETTEXT:
if(IsWindowUnicode(hWnd))
{
StringCchCopyW((LPWSTR) lParam, wParam, L"Hello");
return lstrlenW((LPWSTR) lParam);
}
StringCchCopyA((LPSTR) lParam, wParam, "Hello");
return lstrlenA((LPSTR) lParam);Some of those who are reading this post might think that one should stick to ‘SendMessageW’ for Unicode, and ‘SendMessageA’ for ansi even when sending the message in a particular window. It is smart, but the reality is not as inconvenient as it seems. Through the test, you would notice the system delivering the correct answer no matter whether if you’ve used ‘SendMessageA’ or ‘SendMessageW’, as long as you have delivered the adequate buffer. In other words, ‘SendMessage’ function does all the hard work of appointing the adequate buffer or conversing the ‘IsWindowUnicode’ into ‘WideeCharToMultibyte’ etc. Moreover, other than WM_GETTEXT, ‘sendMessage’ functions as to adequately change the messages that we need the conversion on. All we need to remember is to use ‘SendMessage A’ for ansi, and ‘SendessageW ‘for the Unicode.