윈도우 환경에서 개발 경험이 있는 많은 개발자들이 유니코드(Unicode) 함수에 대해서는 잘 알고 있는데, 정작 유니코드 윈도우에 대해서는 잘 모르는 경향이 있다. 왜 그럴까? 대다수 책에서 이를 직접적으로 설명하지 않기 때문이 그 첫 번째 이유고, 이 내용이 윈도우 API에 의해서 잘 감춰져 있기 때문이 그 두 번째 이유다. 이런 내용을 모르고 고통 받는 많은 루키 개발자들을 위해서 유니코드 윈도우에 대해서 알아보도록 하자.
#0
유니코드 윈도우를 이해하기 위해서는 기본적으로 윈도우에서 제공하는 유니코드 함수들의 동작 구조에 대해서 잘 이해하고 있어야 한다. 윈도우는 문자열을 취급하는 대부분의 함수에 대해서 A가 붙은 멀티바이트(multi-byte) 버전과 W가 붙은 유니코드 버전을 제공한다. GetWindowTextA가 있다면 GetWindowTextW가 있는 셈이다. 물론 각 함수의 기능은 동일하며 A 함수는 파라미터로 char 포인터를, W 함수는 파라미터로 wchar_t 포인터를 전달받는 차이점이 있다. 그렇다면 GetWindowText는 무엇인가? 그건 아래와 같이 매크로로 재정의된 함수다.
#ifdef _UNICODE
#define GetWindowText GetWindowTextW
#else
#define GetWindowText GetWindowTextA
#endif즉, 우리의 빌드 환경이 유니코드라면 GetWindowText는 GetWindowTextW가 되고, 멀티바이트라면 GetWindowTextA가 되는 것이다. 그래서 이 시스템에서는 다음에 나오는 코드와 같이 T형 중립(neutral) 문자형을 사용하고, A, W가 없는 매크로로 재정의된 중립 API를 사용하고, 문자열 처리에도 매크로로 재정의된 T계열 중립 함수를 사용하면 유니코드, 멀티바이트 빌드에 상관 없는 코드를 만들 수 있다.
TCHAR buffer[MAX_PATH];
GetWindowText(hwnd, buffer, ARRAYSIZE(buffer));
_tcscat_s(buffer, ARRAYSIZE(buffer), _T("$"));윈도우 하부 시스템이(window subsystem) 모든 것을 잘 포장하고 있기 때문에 유니코드, 멀티바이트에 대한 고려 없이 프로그램을 작성해도 빌드에 따라서 적절하게 컴파일되고 잘 동작하지만, 정작 변환(conversion) 문제가 발생하면 내부 구조를 모르고는 어디서, 왜 문제가 발생했는지를 알 수 없는 구조라 할 수 있다.
#1
이제 본론으로 들어가서 유니코드 윈도우에 대해서 알아보자. 유니코드 윈도우란 무엇인가? 메시지(message) 처리에 유니코드를 사용하는 윈도우를 말한다. 그러니 당연히 안시(ansi) 윈도우도 있고, 그건 멀티바이트로 메시지를 처리하는 윈도우를 말한다.
똑똑한 개발자라면 메시지를 멀티바이트, 유니코드로 처리한다는 것은 무엇을 의미하는 거지, 라는 새로운 의문이 들 것이다. 간단한 예를 통해서 살펴보도록 하자. WM_GETTEXT라는 메시지를 보자. 이 메시지의 wParam은 글자 개수를, lParam은 글자를 저장할 수 있는 버퍼의 포인터를 지정한다. 문제는 여기서 시작된다. 그렇다면 lParam으로는 유니코드 버퍼를 전달해야 할까? 아니면 멀티바이트 버퍼를 전달해야 할까? 다음과 같은 코드에서 StringCchCopyW를 쓰는 것이 옳은지, StringCchCopyA를 쓰는지가 옳은지를 묻는 것이다.
LRESULT CALLBACK MyWindowProc(HWND hwnd
, UINT msg
, WPARAM w
, LPARAM l)
{
if(msg == WM_GETTEXT)
{
// StringCchCopyW((LPWSTR) l, w, L"MyWindowText");
// or
// StringCchCopyA((LPSTR) l, w, "MyWindowText");
}
return DefWindowProc(hwnd, msg, w, l);
}아마 대부분의 개발자가 이런 것에는 신경 써 본 적이 없을 것이다. 윈도우 하부 시스템이 이를 굉장히 잘 감추고 있기 때문이다. 결론부터 말하면 WM_GETTEXT의 버퍼를 유니코드 윈도우는 유니코드 버퍼로, 안시 윈도우는 멀티바이트 버퍼로 취급해야 한다. 유니코드 윈도우가 멀티바이트 포인터로 이를 처리하고, 반대로 안시 윈도우가 유니코드 문자열로 처리하면 이상하게 동작하는 윈도우가 만들어진다.
#2
그럼 이제 유니코드 윈도우는 어떻게 생성되는지에(created) 대해서 알아보자. 유니코드 윈도우의 생성에는 RegisterClass라는 윈도우 클래스(class) 등록 함수가 개입한다. 물론 이 함수의 어떤 파라미터도 생성될 윈도우가 유니코드인지 아닌지를 결정하는 것은 없다. 그렇다면 어떻게 결정되는 것일까? 바로 호출하는 함수의 종류에 따라서 자동으로 결정한다. RegisterClassW 함수를 사용해서 윈도우 클래스를 등록하면 해당 클래스로 생성되는 윈도우는 유니코드 윈도우가 된다. 반대로 RegisterClassA 함수를 사용해서 윈도우 클래스를 등록하면 해당 윈도우는 멀티바이트 윈도우가 되는 것이다. 이렇게 생성 과정이 감추어져 있기 때문에 많은 개발자가 윈도우가 유니코드인지 아닌지에 대해서 잘 모르고 지나치게 된다.
화면에 존재하는 특정 윈도우가 유니코드 윈도우인지 아닌지는 Spy++ 유틸리티를 통해서 살펴볼 수 있다. Spy++을 사용해서 해당 윈도우의 속성을 살펴보았을 때 다음 그림에 나타난 것처럼 Window Proc 부분에 Unicode라는 말이 있다면 해당 윈도우는 유니코드 윈도우인 것이고, 이런 표시가 없다면 안시 윈도우라고 생각하면 된다.
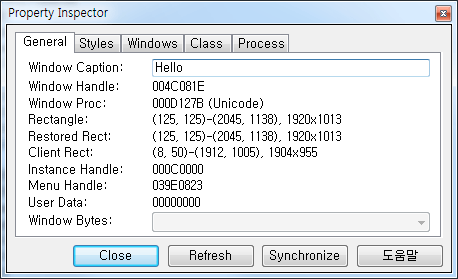
#3
그렇다면 왜 그렇게 윈도우가 유니코드인지 아닌지가 중요할까? 첫째는 이를 모르는 경우에는 메시지 핸들러를 잘못 작성할 수 있기 때문이다. 다음 코드와 같이 윈도우 클래스 등록은 유니코드 윈도우로 해두고 해당 윈도우의 메시지 프로시저의 WM_GETTEXT같은 것은 멀티바이트로 처리해 버리는 것이다. 이러면 당연히 오류가 발생한다.
WNDCLASSEXW wcex;
// ...
wcex.lpfnWndProc = WndProc;
return RegisterClassExW(&wcex);
LRESULT CALLBACK WndProc(HWND wnd
, UINT message
, WPARAM w
, LPARAM l)
{
if(message == WM_GETTEXT)
{
StringCchCopyA((LPSTR) l, w, "Hello");
return lstrlenA((LPSTR) l);
}
return DefWindowProcW(wnd, message, w, l)
}둘째는 윈도우와 관련된 모든 행동을 할 때에 이것은 굉장히 중요하게 작용하기 때문이다. 이를 모르면 엉뚱하게 시스템을 헝클어 버리는 경우가 발생할 수 있다. 특정 윈도우를 서브클래싱을 한다고 해보자. 이 경우에도 유니코드 윈도우라면 SetWindowLongW를, 멀티바이트 윈도우라면 SetWindowLongA를 사용해야 한다. 만약 반대로 호출했다면 원본 윈도우는 유니코드로 메시지를 처리하고, 그걸 서브클래싱한 윈도우 프로시저는 멀티바이트로 처리하는 등의 혼선이 발생한다. 또한 원본 윈도우는 유니코드 윈도우였음에도 SetWindowLongA를 사용해서 서브클래싱하는 순간 해당 윈도우는 안시 윈도우로 변경된다. 이러한 내부 메커니즘을 모르고 서브클래싱을 하면 복잡한 변환 문제에 봉착할 수 있다.
한가지 예를 더 들어보자면 이런 경우도 있다. 보통 메시지 프로시저는 필요한 부분만 작성하고 나머지 부분은 DefWindowProc 함수에 위임한다. 그런데 이 DefWindowProc함수도 DefWindowProcA가 있고, DefWindowProcW가 있다. 여기서 문제가 발생한다. 윈도우는 유니코드로 생성해놓고 DefWindowProcA를 호출한다거나, 윈도우는 멀티바이트로 생성해놓고 DefWindowProcW를 호출하는 것이다. 물론 이렇게 호출하면 대부분의 함수에 대해서 정상 동작하지만 일부 메시지에 대해서는 우리가 기대한대로 동작하지 않는 문제가 발생한다. 아래 윈도우는 그런 경우를 보여주고 있다. RegisterClassA 함수를 사용해서 ANSI 윈도우를 만들고 DefWindowProcW를 호출할 경우다. 정상적으로 처리됐다면 타이틀바에 Hello가 출력돼야 하지만 이상한 글자가 출력되고 있는 것을 볼 수 있다.
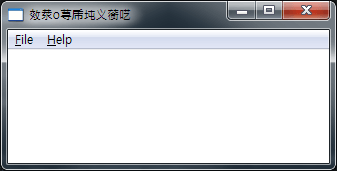
앞서 언급한 실수를 방지하기 위해서는 그저 유니코드 윈도우의 존재와 그것이 처리되는 방식에 대해서만 이해하고 있으면 된다. 여기서 그것이 처리되는 방식이란 유니코드 윈도우는 윈도우 관련 함수에 W계통의 함수를 사용하고, 멀티바이트 윈도우는 A계통의 함수를 사용해야 한다는 것. 그리고 해당 윈도우들은 메시지를 유니코드나 멀티바이트로 처리한다는 점이다. 이것만 기억한다면 바보 같은 실수를 하지 않을 수 있다.
#4
유니코드 윈도우라는 것이 있고, 그것을 잘못 다룰 때 어떤 재앙이 발생하는지에 대해서 살펴봤으니 이제는 당연히 우리가 작업을 하려고 하는 대상 윈도우가 유니코드 윈도우인지 아닌지가 궁금해질 것이다. 어떻게 대상 윈도우가 유니코드인지 아닌지 알 수 있는지 말이다. 이런 용도로 사용하기 위한 아주 간단한 함수가 하나 존재한다. 바로 IsWindowUnicode다. IsWindowUnicode(hwnd)를 호출해서 FALSE가 리턴되면 해당 윈도우는 안시 윈도우고, FALSE가 아닌 값이 반환되면 유니코드 윈도우라는 것을 나타낸다.
#5
끝으로 몇 가지 추가적인 사항에 대해서 좀 더 알아보도록 하자. 앞선 코드를 실제로 테스트해본 개발자라면 윈도우가 유니코드인지 안시인지에 상관 없이 DefWindowProcA나 DefWindowProcW나 아무거나 호출해도 WM_GETTEXT의 메시지의 결과는 정상적으로 나온다는 것을 볼 수 있었을 것이다. 어떻게 이런 것일까? 답은 간단하다. 다음처럼 방어적인 코딩을 했다면 해당 메시지 프로시저는 윈도우의 종류에 관계없이 문자열을 적절하게 처리할 수 있다.
case WM_GETTEXT:
if(IsWindowUnicode(hWnd))
{
StringCchCopyW((LPWSTR) lParam, wParam, L"Hello");
return lstrlenW((LPWSTR) lParam);
}
StringCchCopyA((LPSTR) lParam, wParam, "Hello");
return lstrlenA((LPSTR) lParam);끝으로 이 글을 읽고는 아마도 특정 윈도우에 메시지를 보낼 때에도 해당 윈도우가 유니코드 윈도우라면 SendMessageW를, 안시 윈도우라면 SendMessageA를 써야겠다는 생각을 한 개발자도 있을 것이다. 똑똑한 생각이다. 하지만 현실은 그렇게 불편하지는 않다. 테스트를 해보면 SendMessageA든 SendMessageW든 적절한 버퍼를 전달했다면 제대로 된 값을 반환해 주는 것을 볼 수 있을 것이다. 놀랄 필요는 없다. IsWindowUnicode를 호출해서 해당 윈도우로 적절한 버퍼를 전송하고 그 결과를 다시 우리 입맛에 맞게 WideCharToMultiByte, MultiByteToWideChar를 호출해서 변환하는 그 귀찮은 작업들을 SendMessage가 대신해 주고 있을 뿐이다. 물론 WM_GETTEXT외에도 이렇게 변환이 필요한 모든 메시지에 대해서 SendMessage는 내부적으로 적절하게 변환해주도록 되어 있다. 단지 우리는 SendMessageA를 사용했다면 안시 버퍼를, SendMessageW를 사용했다면 유니코드 버퍼를 전달해야 한다는 사실만 기억하면 된다.