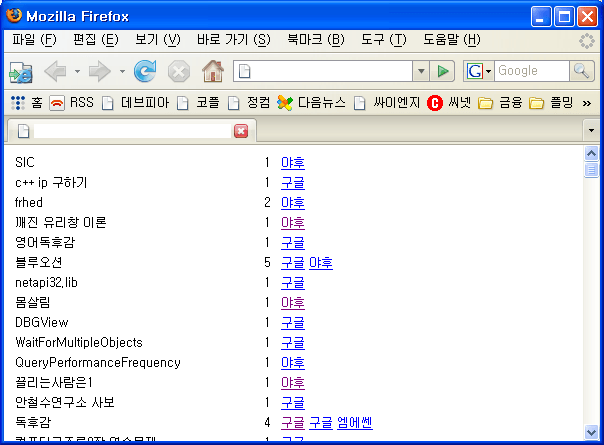
블로그를 운영하면 대부분 자신의 블로그에 어떤 사람들이 찾아오는지 궁금해 집니다.~ 그래서 레퍼러도 뒤지고, 댓글 남기신 분들 사이트도 방문해 보곤 하죠~ 그런데 레퍼러를 보면 대부분의 경우 검색엔진이 많습니다. 물론 제 경우에 ㅎㅎㅎ 이런 경우에 블로그 운영자 입장에서는 검색어에 관심이 가는데 일일히 방문하면서 찾아가기란 귀찮죠~ 그래서 파이썬으로 한번 만들어 봤습니다.
태터툴즈 레퍼러 로그 테이블의 url을 추출해서 검색어를 찾아주는 역할을 합니다. 급조한 거라 버그도 많고, 기능도 미비합니다. ㅎㅎ- 거의 암호 수준이죵... 필요하신 분들은 들고가서 사용해 보세용~ qs() 함수 부분의 디비 정보만 수정해주시면 됩니다. 그리고 호스팅에서 파이썬을 지원하고 MySQLdb같은 거도 설치되어 있어야 합니당. 실행하면 위의 화면처럼 나옵니다.
소스 보기...
#!/usr/local/bin/python
#-\*- coding: utf8 -\*-
import re
import MySQLdb
import urllib
import cgi
def parse\_query(url):
pattern = [
("http://www.google.com/search?.\*q=([^&]\*)"
, 1
, "구글" )
, ("http://www.google.co.kr/search?.\*q=([^&]\*)"
, 1
, "구글")
, ("http://searchplus.nate.com/searchplus/search.plus?.\*query=([^&]\*)"
, 2
, "네이트")
, ("http://search.daum.net/cgi-bin/nsp/search.cgi?.\*q=([^&]\*)"
, 2
, "다음")
, ("http://search.msn.co.kr/results.aspx?.\*q=([^&]\*)"
, 2
, "엠에쎈")
, ("http://kr.search.yahoo.com/search?.\*p=([^&]\*)"
, 2
, "야후")
, ("http://search.paran.com/search/index.php?.\*KeyWord=([^&]\*)"
, 1
, "파란")
, ("http://search.naver.com/search.naver?.\*query=([^&]\*)"
, 2
, "네이버")
, ("http://search.live.com/results.aspx?.\*q=([^&]\*)"
, 1
, "라이브닷컴") ]
for p in pattern:
r = re.compile(p[0])
m = r.search(url)
if m:
q = urllib.unquote(urllib.unquote\_plus(m.group(1)))
return (m.group(0), q, p[1], p[2])
def qs():
#db = MySQLdb.connect('localhost', 'id', 'pass', 'dbname')
db = MySQLdb.connect('', '', '', '')
cursor = db.cursor()
#cursor.execute('''select \* from tt\_RefererLogs''')
cursor.execute('''select \* from tableName''')
result = cursor.fetchall()
urls = []
for r in result:
urls.append(r[2])
return urls
def main():
cnt = 0
urls = qs()
results = []
for x in urls:
k = parse\_query(x)
if k:
results.append(k)
ur = []
for x in results:
finded = 0
for y in ur:
if x[1] == y[0]:
finded = 1
y[3] = y[3] + 1
sfinded = 0
for k in y[2]:
if x[0] == k[0]:
sfinded = 1
break
if sfinded == 0:
y[2].append([x[0], x[3]])
break
if finded == 0:
ur.append([x[1], x[2], [[x[0], x[3]]], 1])
buf = """<table cellspacing=1 cellpadding=2 style="font-size:9pt;">"""
for k in ur:
if k[1] == 2:
try:
q = unicode(k[0], "euc-kr").encode("utf8")
except UnicodeDecodeError:
q = k[0]
else:
q = k[0]
s = ""
for v in k[2]:
name = v[1]
s += """<a href="%s">%s</a> """ % (v[0], name)
buf += """
<tr><td>%s</td>
<td>%d</td>
<td>%s</td></tr> """ % (q, k[3], s)
cnt = cnt + 1
print "Content-type: text/html\n"
print """<html><head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
</head><body>
%s
</body></html>""" % (buf)
main()